This year in LLVM (2024)
Another year has passed, so it’s once again time for my yearly summary blog post. As usual, this summary is mostly about my own work, and only covers the more significant / higher level items.
ptradd
I started working on the ptradd migration last year, but the first significant steps towards it only landed this year. The goal is to move away from the type-based/structural getelementptr (GEP) instruction, to a ptradd instruction, which does no more and no less than adding an offset to a pointer. The value of that offset is computed using normal mul/add instructions, if necessary.
The general implementation approach is to gradually canonicalize all getelementptrs into getelementptr i8 representation, which is equivalent to ptradd, at which point we can remove support for specifying other types.
The first step was to canonicalize constant-offset GEPs. For example, getelementptr i32, ptr %p, i64 1 becomes getelementptr i8, ptr %p, i64 4, removing the implicit multiplication. Just this step already fixed a number of optimization failures caused by the old representation. Of course, it also exposed new optimization weaknesses, like insufficient select unfolding in SROA.
The second step was to canonicalize constant-expression GEPs as well. That is, getelementptr (i32, ptr @g, i64 1) is converted to getelementptr (i8, ptr @g, i64 4). However, this first required a change to how the inrange attribute on GEP constant expressions is represented.
; Old:
getelementptr inbounds ({ [4 x ptr], [4 x ptr] }, ptr @vt, i64 0, inrange i32 1, i64 2)
; New:
getelementptr inbounds inrange(-16, 16) (i8, ptr @vt, i64 48)
inrange is a niche feature that is only used when generating vtables. It specifies that the GEP result can only be accessed in a limited range, which enables global splitting. Previously, this range was specified by marking a GEP index as inrange, limiting any accesses to occur “below” that index only. The new representation explicitly specifies the range of valid offsets instead, which removes the dependence on the structural GEP type.
The next step for this project will be to canonicalize getelementptr instructions with variable offsets as well, in which case we will have to emit explicit offset arithmetic. I hope we can take this step next year.
getelementptr nuw
I have worked on a number of new instruction flags, the most significant of which are probably the nusw (no unsigned-signed wrap) and nuw (no unsigned wrap) flags for getelementptr.
Getelementptr instructions already supported the inbounds flag, which indicates that the pointer arithmetic cannot go outside the underlying allocated object. This also implies that the addition of the pointer, interpreted as an unsigned number, and the offset, interpreted as a signed number, cannot wrap around the address space.
This implied property can now be specified using the nusw flag, without also requiring the stronger inbounds property. The intention of this change is to be more explicit about which property transforms actually need, and to allow frontends (e.g. Rust) to experiment with alternative semantics that don’t require the hard to formalize inbounds concept.
However, the much more useful new flag is nuw, which specifies that the addition of the address and the offset does not wrap in an unsigned sense. Combined with nusw (or inbounds), it implies that the offset is non-negative. This flag fixes two key problems.
The first are bounds/overflow check elimination failures caused by not knowing that an offset is non-negative. For example, if we have a check like ptr + offset >= ptr, we want it to optimize to true, for the case where offset is unsigned and pointer arithmetic cannot wrap. Previously this was not possible, because the frontend had no way to convey that this is a valid optimization to LLVM.
The second is accesses to structures like struct vec { size_t len; T elems[N]; }. The nuw flag allows us to convey that vec.elems[i] cannot access the len field using a negative i.
The core work for the new GEP flags is complete. Both alias analysis and comparison simplification can take advantage of them. However, there is still a good bit of work that can be done to preserve the new flags in all parts of the compiler.
One interesting complication of the nuw flag is the interaction with incorrectly implemented overflow checks in C code. The ptr + offset >= ptr example above is something we want to be able to optimize, because this kind of pattern can, for example, appear when using a hardened STL implementation.
However, a C programmer might also write literally that check with the intention of detecting an overflowing pointer addition. This is incorrect, because ptr + offset will already trigger UB on overflow (or, in fact, just going out of bounds of the underlying object). These incorrect overflow checks will now be optimized away.
I have extended the -Wtautological-compare warning to catch trivial cases of this problem, and the -fsanitize=pointer-overflow warning catches the issue reliably – if you have test coverage.
trunc nuw/nsw
Another new set of instruction flags are the nuw and nsw flags on trunc. These flags specify that only zero bits (nuw) or sign bits (nsw) are truncated. The important optimization property of these new flags is that zext (trunc nuw (x)) is just x and sext (trunc nsw (x)) is also just x.
These kinds of patterns commonly occur when booleans are converted between their i1 value and i8 memory representation, or during widening of induction variables.
Unfortunately, rolling out these flags did not go as smoothly as expected. While we do take advantage of the new flags to some degree, we don’t actually perform the motivating zext (trunc nuw (x)) -> x fold yet, and instead keep folding this to and x, 1 (for i1). The reason is that completely eliminating the zext/trunc loses the information that only the low bit may be set. We need to strengthen some other optimizations before we’ll be able to take this step.
icmp samesign
Yet another new instruction flag is samesign on icmp instructions. As one might guess from the name, it indicates that both sides of the comparison have the same sign, i.e. are both non-negative or both negative.
If samesign is set, we can freely convert between signed and unsigned comparison predicates. The motivation is that LLVM generally tries to canonicalize signed to unsigned operations, including for comparisons. So something like icmp slt will become icmp ult if we can prove the operands have the same sign. However, after this has happened, later passes may have a hard time understanding how this unsigned comparison relates to another signed comparison that has related operands. The samesign flag allows easily converting back to a signed predicate when needed.
The bring-up work for samesign has only just started, so there’s barely any visible optimization impact yet.
Improvements to capture tracking
Capture tracking, also known as escape analysis, is critical for the quality of memory optimizations. Once a pointer has “escaped”, we can no longer accurately track when the pointer may be accessed, disabling most optimizations.
LLVM currently provides a nocapture attribute, which indicates that a call does not capture a certain parameter. However, this is an all-or-nothing attribute, which does not allow us to distinguish several different kinds of captures.
I have proposed to replace nocapture with a captures(...) attribute, which allows a finer-grained specification. In particular, it separates capturing the address of the pointer, which is information about its integral value, and capturing the provenance of the pointer, which is the permission to perform memory accesses through the pointer. Provenance captures are what we usually call an “escape”, and only provenance captures are relevant for the purposes of alias analysis.
Address and provenance are often captured together, but not always. For example, a pointer comparison only captures the address, but not the provenance. Rust makes address-only capture particularly clear with its strict provenance APIs, where ptr.addr() only returns the address of the pointer, without its provenance.
The new captures attribute additionally allows specifying whether the full provenance is captured, or only read-only provenance. For example, a & (Freeze) reference argument in Rust could use readonly captures(address, read_provenance) attributes to indicate that not only does the function not modify the argument directly, it also can’t stash it somewhere and perform a modification through it after the function returns. As many optimizations are only inhibited by potential writes (“clobbers”), this is an important distinction.
I have implemented the first step for this proposal and plan to continue this in the new year. Furthermore, this is only the first step towards improving capture analysis in LLVM. Some followups I have in mind are:
- Support
capturesattribute (or something similar) onptrtointinstructions. This would allow us to accurately represent the semantics ofptr.add()in Rust. - Support
!capturesmetadata on stores. This would allow us to indicate that values passed toprintln!()in Rust are read-only escapes. - Add a first-class operation for pointer subtraction, which is currently done through
ptrtoint.
Three-way comparison intrinsics
Three-way comparisons return the comparison result as one of -1 (smaller), 0 (equal) or 1 (greater). Historically, LLVM did not have a canonical representation for such comparisons, instead they could be represented using a large number of different instruction sequences, none of which produced ideal optimization outcomes and codegen for all targets.
I proposed adding three-way comparison intrinsics llvm.ucmp and llvm.scmp to represent such comparisons. Volodymyr Vasylkun implemented these as a GSoC project, including high-quality codegen, various middle-end optimizations and canonicalization to the new intrinsics.
There is a short blog post on the topic, which is worth reading, and has an example illustrating how codegen improves for the C++ spaceship operator <=>.
APInt assertions
When constructing an arbitrary-precision integer (APInt) from a uint64_t, we previously performed implicit truncation: If the passed value was larger than the specified bit width, we’d just drop the top bits. Sometimes, this is exactly what we want, but in other cases it hides a bug.
A particular common issue is to write something like APInt(BW, -1) without setting the isSigned=true flag. This would work correctly for bit widths <= 64, and then produce incorrect results for larger integers, which have much less coverage (both in terms of tests and in-the-wild usage).
The APInt constructor now asserts that the passed value is a valid N-bit signed/unsigned integer. It took a good while to get there, because a lot of existing code had to be adjusted.
This work is not fully complete yet, because ConstantInt::get() still enables implicit truncation. Changing this will require more work to adjust existing code.
Quality of life improvements
I have made a number of quality of life improvements when it comes to things I do often. Part of this are improvements to the IR parser in three areas:
- Do not require declarations or type mangling for intrinsics. You can now write
call i32 @llvm.smax(i32 %x, i32 %y)and the parser will automatically determine the correct type mangling and insert the intrinsic declaration. This removes a big annoyance when writing proofs. - Don’t require unnamed values to be consecutive. This makes it much easier to reduce IR with unnamed values by hand.
- Allow parsing of incomplete IR under the
-allow-incomplete-iroption. This makes it easy to convert things like-print-after-alloutput into valid IR.
Additionally, I have added support for pretty crash stacks for the new pass manager. This means that crashes now print which pass (with which options) crashed on which function.
I have also written an InstCombine contributor guide. This helps new contributors write good PRs for InstCombine (and the middle-end in general), which makes the review process a lot more efficient.
Another improvement to reviewer life was to remove complexity-based canonicalization. While well-intentioned, in practice this transform just made it hard to write test coverage that does what you intended, which especially new contributors often struggled with. This removes the need for the “thwart” test pattern.
Compilation-time
I have not done much work on compile-time myself this year, but other people have picked up the slack, so I’ll provide a summary of their work. Here is how compile-time developed since the start of 2024:
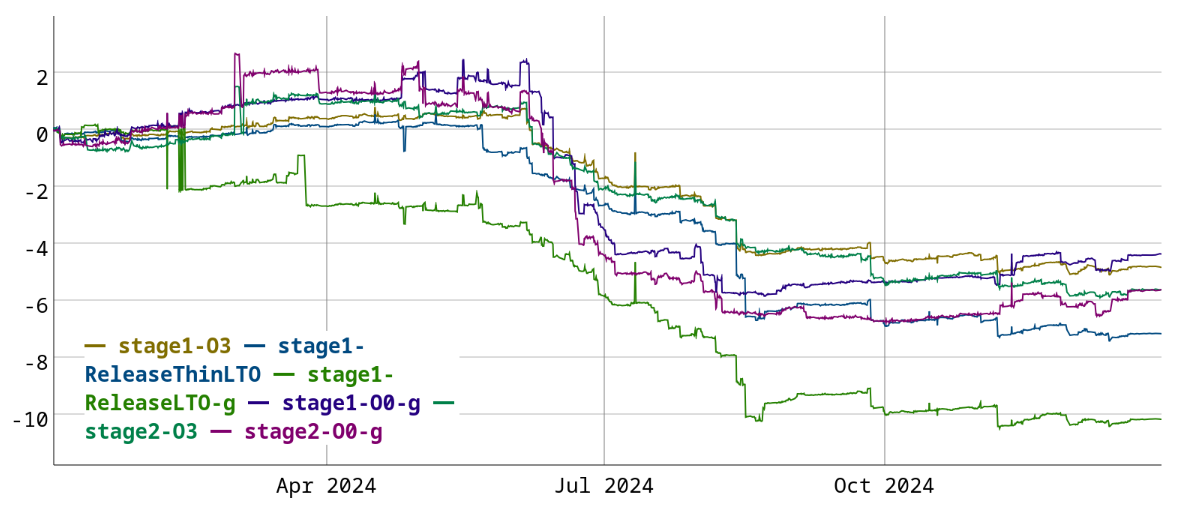
The largest wins this year are in the ReleaseLTO-g configuration (about 10%). A big reason for this is the switch from debug intrinsics to debug records, which moves debug information out of the instruction list. This benefits all builds with debuginfo, but particularly optimized debuginfo builds.
The two commits switching to the new representation amount to about 4% improvement (1, 2). There will be some additional improvements once support for debug intrinsics is removed.
Unoptimized O0-g configurations saw an improvement of about 4-6% this year, mostly thanks to a concerted effort by aengelke to improve unoptimized build times for JIT use cases.
One of the largest individual wins was adding a fast-path to RegAllocFast, the O0 register allocator, for a 0.8% improvement. Caching the register alias iterator also produced a 0.6-0.8% improvement. Not computing unnecessary symbol names gave a 0.4% improvement and using a bump-pointer allocator for MCFragments gave a 0.5% improvement. Though that one came at a cost of increased max-rss, so I’m not sure if it was a good tradeoff. There were also many other small improvements, that add up to a large overall improvement.
One regression for unoptimized builds was to stop using -mrelax-all. While this was a 0.6% compile-time regression, it also decreased binary size by 4-5%, which is a pretty good deal.
Optimized builds also saw wins of about 5-7%. One of the key changes was the introduction of block numbers, which assign a unique number to each basic block in a function. These can then be used to map blocks to dominator tree nodes (1, 2) using a vector instead of a hashtable, significantly reducing the cost of accesses. This results in a ~1.2% improvement (1, 2), and will probably be useful for more things in the future.
Another interesting changes is to not rerun the same pass if the IR did not change in the meantime, for a 0.5% improvement. I think this is currently less effective than it could be, because we have some passes that keep toggling the IR between two forms (e.g. adding and removing LCSSA phi nodes).
A somewhat different compile-time improvement was a change to clang’s bitfield codegen. This resulted in a 0.3-0.6% improvement on stage 2 builds (where clang is compiled with clang). It’s an optimization improvement that has a large enough impact to affect compilation times.
There was also a change that improves the time to build clang, which was the introduction of DynamicRecursiveASTVisitor, and migration of most visitors to use it. This switches many AST visitors away from huge CRTP template instantiations to using dynamic dispatch. The PR switching most visitors improved clang build times by 2% and the size of the resulting binary by nearly 6% (!). This does come at a small compile-time cost for small files, due to the increase in dynamic relocations.
To close with some optimizations I actually did myself, I implemented a series of improvements to the SmallPtrSet data structure (1, 2, 3), to make sure that the fast-path is as efficient as possible. These add up to a 0.7% improvement (1, 2, 3).
I also made a series of improvements to ScalarEvolution::computeConstantDifference() to make it usable in place of ScalarEvolution::getMinusSCEV() during SLP vectorization. This was a 10% improvement on one specific benchmark.
Rust
I updated Rust to LLVM 18 and LLVM 19 this year. Both of these came with very nice perf results (LLVM 18, LLVM 19).
The LLVM 18 upgrade had quite a few complications, but probably the most disproportionately annoying was the fact that the LLVM soname changed from libLLVM-18.so to libLLVM.so.18.1, with libLLVM-18.so being a symlink now. Threading the needle between all the constraints coming from Rust dylib linking, rustup and LLVM, this ultimately required converting libLLVM-18.so into a linker script.
The LLVM 19 upgrade went pretty smoothly. One change worth mentioning is that LLVM 19 enabled the +multivalue and +extern-types wasm features by default. We could have handled this in various ways, but the decision was that Rust’s wasm32-unknown-unknown target should continue following Clang/LLVM defaults over time. There is a blog post with more information.
We have also reached the point where we align with upstream LLVM very closely: We only carry a single permanent patch, and most backports are now handled via upstream patch releases, instead of Rust-only backports.
I also implemented what has to be my lowest-effort compile-time win ever, which is to disable LLVM IR verification in production builds more thoroughly. This is a large win for debug builds.
Finally, I presented a keynote at this year’s LLVM developer meeting with the title “Rust ❤️ LLVM” (slides, recording), discussing how Rust uses LLVM and some of the challenges involved. I had a lot of fruitful discussions on the topic as a result. The only downside is that people now think I know a lot more about Rust than I actually do…
I’d also like to give a shout-out to DianQK, who has helped a lot with tracking down and fixing LLVM bugs that affect Rust.
Packaging
This year, the way LLVM is packaged for Fedora, CentOS Stream and RHEL underwent some major changes. This is something the entire LLVM team at Red Hat worked on to some degree.
The first, and most significant, is that we now build multiple LLVM subprojects (llvm, clang, lld, lldb, compiler-rt, libomp, and python-lit) as part of a single build, while keeping the separate binary RPMs. Previously, we used standalone builds for each subproject.
While standalone builds have their upsides (like faster builds if you’re only changing one subproject), they are very much a second class citizen in upstream LLVM, and typically only used by distros. Using a monorepo build moves us to a better supported configuration.
Additionally, it simplifies the build process, because we previously had to do a coordinated rebuild of 14 different packages for each LLVM point release. For LLVM 19, we’re down to a single build on RHEL and 8 builds on Fedora, which ships more subprojects. For LLVM 20 we should get down to 4 builds, as we merge more subprojects into the monorepo build.
The second change is related to the nightly snapshot builds we have been offering for a while already. These are now maintained directly on the Fedora rawhide branch of rpms/llvm, which supports building both the current LLVM version (19) and snapshots for the upcoming one (20) from the same spec file. This avoids divergence between the two branches, and (in theory) reduces an LLVM major version upgrade to a change in the build configuration.
The final change is to consolidate the spec file for all operating systems we build for. The Fedora rawhide spec file can also be used to build for RHEL 8, 9 and 10 now. Again, this helps to prevent unintentional divergence between operating systems. Additionally, it means that LLVM snapshot builds are now available for RHEL as well.
Other
I have been nominated as the new lead maintainer for LLVM, taking over from Chris Lattner. What does this mean? Even more code review, of course! According to graphite, I’ve reviewed more than 2300 pull requests last year. I have also spent some time getting LLVM’s badly outdated list of maintainers up to date (though this isn’t entirely complete yet).
N3322, the C proposal I worked on together with Aaron Ballman, has been accepted for C2y, making memcpy(NULL, NULL, 0) well-defined.
To close this blog post, I’d like to thank dtcxzyw for his incredible work on LLVM, both in identifying and fixing numerous miscompilation issues, and implementing many optimizations with demonstrable usefulness. llvm-opt-benchmark has quickly become an indispensable tool for analyzing optimization impact.