Make LLVM fast again
The front page of the LLVM website proudly claims that:
Clang is an “LLVM native” C/C++/Objective-C compiler, which aims to deliver amazingly fast compiles […]
I’m not sure whether this has been true in the past, but it certainly isn’t true now. Each LLVM release is a few percent slower than the last. LLVM 10 put some extra effort in this area, and somehow managed to make Rust compilation a whole 10% slower, for as yet unknown reasons.
One might argue that this is expected, as the optimization pipeline is continuously being improved, and more aggressive optimizations have higher compile-time requirements. While that may be true, I don’t think it is a desirable trend: For the most part, optimization is already “good enough”, and additional optimizations have the unfortunate trend to trade large compile-time increases for very minor (and/or very rare) improvements to run-time performance.
The larger problem is that LLVM simply does not track compile-time regressions. While LNT tracks run-time performance over time, the same is not being done for compile-time or memory usage. The end result is that patches introduce unintentional compile-time regressions that go unnoticed, and can no longer be easily identified by the time the next release rolls out.
Tracking LLVM compile-time performance
The first priority then is to make sure that we can identify regressions accurately and in a timely manner. Rust does this by running a set of benchmarks on every merge, with the data available on perf.rust-lang.org. Additionally, it is possible to run benchmarks against pull requests using the @rust-timer bot. This helps evaluate changes that are intended to improve compile-time performance, or are suspected of having non-trivial compile-time cost.
I have set up a similar service for LLVM, with the results viewable at llvm-compile-time-tracker.com. Probably the most interesting part are the relative instructions and max-rss graphs, which show the percentual change relative to a baseline. I want to briefly describe the setup here.
The measurements are based on CTMark, which is a collection of some larger programs that are part of the LLVM test suite. These were added as part of a previous attempt to track compile-time.
For every tested commit, the programs are compiled in three different configurations: O3, ReleaseThinLTO and ReleaseLTO-g. All of these use -O3 in three different LTO configurations (none, thin and fat), with the last one also enabling debuginfo generation.
Compilation and linking statistics are gathered using perf (most of them), GNU time (max-rss and wall-time) and size (binary size). The following statistics are available:
instructions (stable and useful)
max-rss (stable and useful)
task-clock (way too noisy)
cycles (noisy)
branches (stable)
branch-misses (noisy)
wall-time (way too noisy)
size-total (completely stable)
size-text (completely stable)
size-data (completely stable)
size-bss (completely stable)
The most useful statistics are instructions, max-rss and size-total/size-text, and these are the only ones I really look at. “instructions” is a stable proxy metric for compile-time. Instructions retired is not a perfect metric, because it discounts issues like cache/memory latency, branch misprediction and ILP, but most of the performance problems affecting LLVM tend to be simpler than that.
The actual time metrics task-clock and wall-time are too noisy to be useful and also undergo “seasonal variation”. This could be mitigated by running benchmarks many times, but I don’t have the compute capacity to do that. Instructions retired on the other hand is very stable, and allows us to confidently identify compile-time changes as small as 0.1%.
Max-rss is the maximum resident set size, which is one possible measure of memory usage (a surprisingly hard concept to pin down). In aggregate, this metric is also relatively stable, with the exception of the ThinLTO configuration.
The binary size metrics are not really useful to judge compile time, but they do help to identify whether a change has impact on codegen. A compile-time regression that results in a code-size change is at least doing something. And the amount and structure of IR during optimization can have a significant impact on compile-time.
Different benchmarks have different variance. The detailed comparison pages for individual commits, like this max-rss comparison, highlight changes in red/green that are likely to be significant. Highlighting starts at 3 sigma (no color) and ends at 4 sigma (a clear red/green). The highlighting has no relation to the size of the change, only to its significance. Sometimes a 0.1% change is significant, and sometimes a 10% change is not significant.
In addition to the three configurations, the comparison view also shows link-only data for the ThinLTO/LTO configurations, as these tend to be a build bottleneck. It’s also possible to show data for all the individual files (the “per-file details” checkbox).
The benchmark server communicates exclusively over Git: Whenever it is idle, it fetches the master branch of LLVM upstream, as well as any branches starting with perf/ from a number of additional LLVM forks on GitHub. These perf/ branches can be used to run experiments without committing to upstream. If anyone is interested in doing LLVM compile-time work, I can easily add additional forks to listen to.
After measurements have been performed, the data is pushed to the llvm-compile-time-data repository, which stores the raw data. The website displays data from that repository.
The server this runs on only has 2 cores, so a full LLVM build can take more than two hours. For smaller changes, building LLVM from ccache and compiling the benchmarks takes about 20 minutes. This is too slow to test every single commit, but we don’t really need to do that, as long as we automatically bisect any ranges with significant changes.
Compile-time improvements
Since I started tracking, the geomean compile-time on CTMark has been reduced by 8-9%, as the following graph shows.
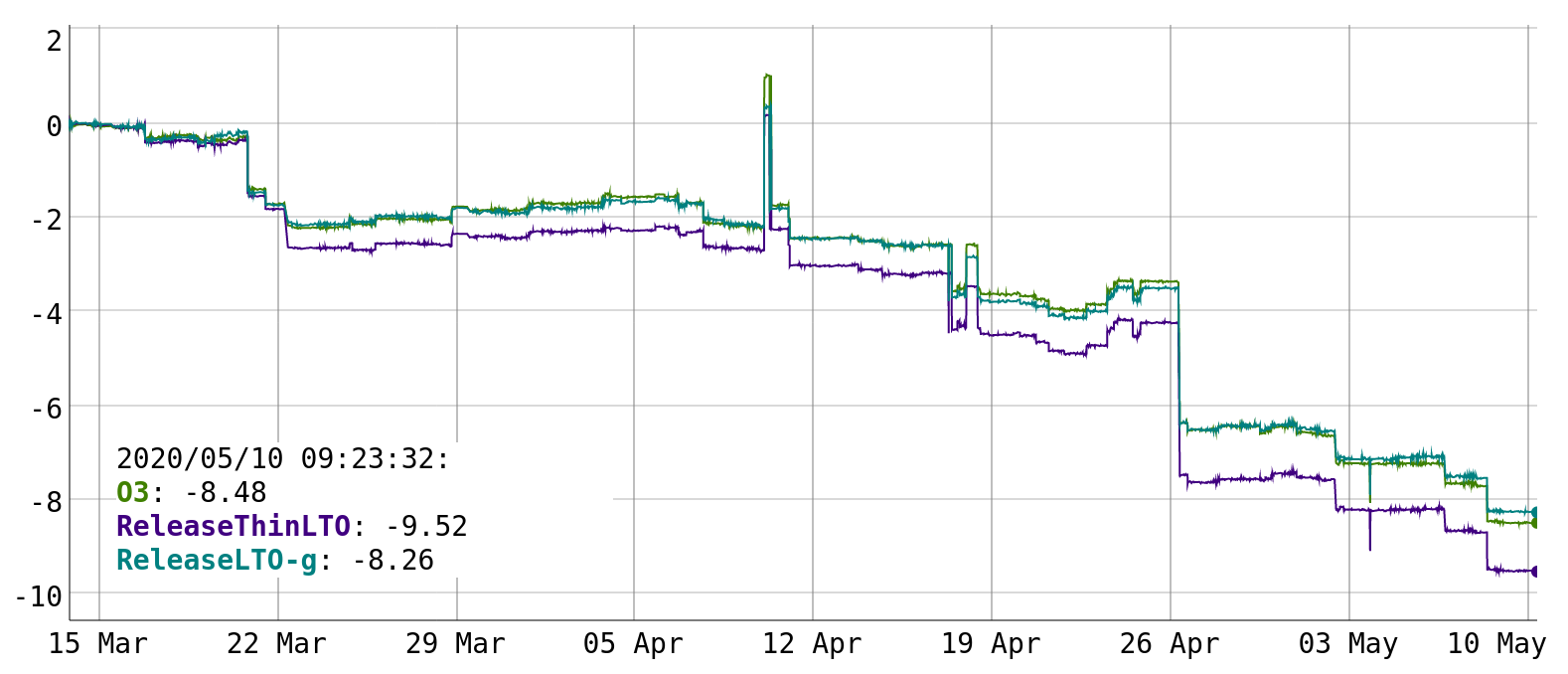
Most compile-time improvements and regressions tend to be small, with only few large jumps. A change of 0.25% is already worth looking at. A change of 1% is large. In the following I’ll describe some of the improvements that I have implemented over the last few weeks.
The largest one, and a complete outlier in terms of impact, was switching string attributes to use a map, which gave a 3% improvement.
Attributes in LLVM come in two forms: Enum attributes, which are predefined (e.g. nonnull or dereferenceable), and string attributes, which can be free-form ("use-soft-float"="true"). While enum attributes are stored in a bitset for efficient lookup, string attributes are only accessible by scanning through the whole attribute list and comparing attribute names one by one. As Clang tends to generate quite a few function attributes (20 enum and string attributes are normal) this has a large cost, especially when it comes to lookup of attributes which are not actually set. The patch introduces an additional map from name to attribute to make this lookup more efficient.
A related change that is still under review is to convert the "null-pointer-is-valid" string attribute into an enum attribute, which will give another 0.4% improvement. This is one of the most commonly queried string attributes, because it influences pointer semantics fundamentally.
One common source of performance issues in LLVM are computeKnownBits() queries. These are recursive queries that determine whether any bits of a value are known to be zero or one. While the query is depth-limited, it can still explore quite a few instructions.
There’s two ways to optimize this: Make the query cheaper, or make less calls to it. To make the query cheaper, the most useful technique is to skip additional recursive queries if we already know that we cannot further improve the result.
Short-circuiting GEP calculations gives us a 0.65% improvement. Getelementptr essentially adds type-scaled offsets to a pointer. If we don’t know any bits of the base pointer, we shouldn’t bother computing bits of the offsets. Doing the same for add/sub instructions gives a more modest 0.3% improvement.
Of course, it is best if we can avoid calling computeKnownBits() calls in the first place. InstCombine used to perform a known bits calculation for each instruction, in the hope that all bits are known and the instruction can be folded to a constant. Predictably, this happens only very rarely, but takes up a lot of compile-time.
Removing this fold resulted in a 1% improvement. This required a good bit of groundwork to ensure that all useful cases really are covered by other folds. More recently, I’ve removed the same fold in InstSimplify, for another 0.8% improvement.
Using a SmallDenseMap in hot LazyValueInfo code resulted in a 0.5% improvement. This prevents an allocation for a map that usually only has one element.
While looking into sqlite3 memory profiles, I noticed that the ReachingDefAnalysis machine pass dominated peak memory usage, which I did not expect. The core problem is that it stores information for each register unit (about 170 on x86) for each machine basic block (about 3000 for this test case).
I applied a number of optimizations to this code, but two had the largest effect: First, avoiding full reprocessing of loops, which was a 0.4% compile-time improvement and 1% memory usage improvement on sqlite. This is based on the observation that we don’t need to recompute instruction defs twice, it is enough to propagate the already computed information across blocks.
Second, storing reaching definitions inside a TinyPtrVector instead of a SmallVector, which was a 3.3% memory usage improvement on sqlite. The TinyPtrVector represents zero or one reaching definitions (by far the most common) in 8 bytes, while the SmallVector used 24 bytes.
Changing MCExpr to use subclass data was a 2% memory usage improvement for the LTO with debuginfo link step. This change made previously unused padding bytes in MCExpr available for use by subclasses.
Finally, clearing value handles in BPI was a 2.5% memory usage improvement on the sqlite benchmark. This was a plain bug in analysis management.
One significant compile-time improvement that I did not work on is the removal of waymarking in LLVMs use-list implementation. This was a 1% improvement to compile-time, but also a 2-3% memory usage regression on some benchmarks.
Waymarking was previously employed to avoid explicitly storing the user (or “parent”) corresponding to a use. Instead, the position of the user was encoded in the alignment bits of the use-list pointers (across multiple pointers). This was a space-time tradeoff and reportedly resulted in major memory usage reduction when it was originally introduced. Nowadays, the memory usage saving appears to be much smaller, resulting in the removal of this mechanism. (The cynic in me thinks that the impact is lower now, because everything else uses much more memory.)
Of course, there were also other improvements during this time, but this is the main one that jumped out.
Regressions prevented
Actively improving compile-times is only half of the equation, we also need to make sure that regressions are reverted or mitigated. Here are some regressions that did not happen:
A change to the dominator tree implementation caused a 3% regression. This was reverted due to build failures, but I also reported the regression. To be honest I don’t really understand what this change does.
A seemingly harmless TargetLoweringInfo change resulted in a 0.4% regression. It turned out that this was caused by querying a new "veclib" string attribute in hot code, and this was the original motivation for the attribute improvement mentioned previously. This change was also reverted for unrelated reasons, but should have much smaller performance impact when it relands.
A change to the SmallVector implementation caused a 1% regression to compile-time and memory usage. This patch changed SmallVector to use uintptr_t size and capacity for small element types like char, while normally uint32_t is used to save space.
It turned out that this regression was caused by moving the vector grow implementation for POD types into the header, which (naturally) resulted in excessive inlining. The memory usage did not increase because SmallVectors take up more space, but because the clang binary size increased so much. An improved version of the change was later reapplied with essentially no impact.
The emission of alignment attributes for sret parameters in clang caused a 1.4% regression on a single benchmark.
It turned out that this was caused by the emission of alignment-preserving assumptions during inlining. These assumptions provide little practical benefit, while both increasing compile-time and pessimizing optimizations (this is a general LLVM issue in the process of being addressed with a new operand-bundle based assumption system).
We previously ran into this issue with Rust and disabled the functionality there, because rustc emits alignment information absolutely everywhere. This is contrary to Clang, which only emits alignment for exception cases. The referenced sret change is the first deviation from that approach, and thus also the first time alignment assumptions became a problem. This regression was mitigated by disabling alignment assumptions by default.
One regression that I failed to prevent is a steady increase in max-rss. This increase is caused primarily by an increase in clang binary size. I have only started tracking this recently (see the clang binary size graph) and in that time binary size increased by nearly 2%. This has been caused by the addition of builtins for ARM SVE, such as this commit. I’m not familiar with the builtins tablegen system and don’t know if they can be represented more compactly.
Conclusion
I can’t say a 10% improvement is making LLVM fast again, we would need a 10x improvement for it to deserve that label. But it’s a start…
One key problem here is the choice of benchmarks. These are C/C++ programs compiled with Clang, which generates very different IR from rustc. Improvements for one may not translate to improvements for the other. Changes that are neutral for one may be large regressions for the other. It might make sense to include some rustc bitcode outputs in CTMark to give non-Clang frontends better representation.
I think there is still quite a lot of low-hanging fruit when it comes to LLVM compile-time improvements. There’s also some larger ongoing efforts that have mostly stalled, such as the migration to the new pass manager, the migration towards opaque pointers (which will eliminate many bitcast instructions), or the NewGVN pass.
Conversely, there are some ongoing efforts that might make for large compile-time regressions when they do get enabled, such as the attributor framework, the knowledge retention framework and MemorySSA-based DSE.
We’ll see how things look by the time of the LLVM 11 release.